

For a long time in computer graphics, we’d regularly see new graphics card launched on an annual basis (and sometimes sooner than that), but for just about two years now, gamers in particular have been been left with the Nvidia GeForce GTX 10 series, powered by the companies’ Pascal architecture. But finally after months of anticipation and waiting, Nvidia announce Turing. The company claim it’s the most important update to their product lineup in over 10 years, which was the time we saw the company introduce the Unified Shader model and CUDA to the world.
You see, before that, GPUs didn’t have unified shaders, and instead of separate hardware for vertex and pixel shaders (and so on), GPUs were now capable of running instructions across hundreds of processors which could be leveraged to perform a wide variety of tasks. This was important because different game engines would place different demands on the graphics cards, and demands would even fluctuate on frame by frame basis. Furthermore, now GPUs could do so much more than process image data, and as we’ve seen over the past several years, DeepLearning, AI, Physics and so much more has been accelerated thanks to graphics cards.
If I were Nvidia and giving an elevator pitch of how the Turing functions and performs, I’d tell you to imagine their Volta architecture, but improving on it in almost every conceivable way. It combines the standard rasterization that we’ve grown accustomed to in computer graphics for so many years, but also adds in RT cores for real time RayTracing and also increases performance of the Tensor Cores to allow AI to come into play and improve performance further still.

For this article we’ll focus on an overview of Nvidia’s Turing architecture, and also the Quadro RTX 5000, which we can almost certainly guess will be an accurate depiction (with some obvious concessions) of the RTX 2080, and we’ll also take a peak at leaked benchmarks too.
Unfortunately, details are still scarce concerning the workings of the RT cores, but as the name implies they serve as dedicated processors with the sole responsibility of handling Ray Tracing. During his on stage presentation, Jensen Huang made it clear they do so in a number of critical ways. The first is they accelerate Ray-Triangle intersection and we also have Bounding Volume Hierarchy (BHV). What this allows is for the GPU to figure out what what a ‘ray’ of light is doing. RT Cores allows the GPU to figure out which rays are actually hitting surfaces (primatives) and then with those checks it can then continue the calculation. The current Quadro cards are capable of casting 10 Billion Giga rays per second, so here we see Turing enjoy a 25x (not a typo) performance advantage compared to Pascal.

For gamers, the big question is how this will work alongside the Tensor cores in the GeForce RTX 2080 and other cards. According to Nvidia, they also use Tensor cores as a key component to speed up ray tracing, by needing to cast fewer rays it’ll instead rely on AI to denoise the lower resolution image. Here is the impressive thing – with the Quadro based cards at the least, we see 125 TFLOPS of FP32 performance (full precision), 250 TOPS with INT8, and 500 TOPS with INT4.
Nvidia still aren’t revealing all of the information, but the company are touting a 6x increase in performance versus Pascal… although failed to mention the specific Pascal parts, so that’s a little disappointing.

The Turing SM (Streaming Multiprocessor) has a number of changes compared to Pascal, one of those is the ability to execute Floating and Integer based operations simultaneously. So far, on the parts shown with Quadro, Nvidia state 16 TFLOPS and 16 TIPS. This is a byproduct of its Volta heritage, and we had seen both the Integer and FP units have their own dedicated cores. One of the things that wasn’t announced was if we’d see low precision FP16 support, something that’s already supported in Tensor cores. AMD have similarly supported this with their Vega architecture (Rapid Packed Math) and Nvidia also supported it with Volta so its almost certain that’ll continue with Turing.

One of the other mysteries right now is Unified Cache Architecture. Unfortunately, as of now there’s no official SM Diagrams available – so whether or not this is Volta like (where L1 cache was merged with Shared memory) or if it’s something different entirely.
The whole GPU is 18.6 Billion transistors, compared to 11.8 of Pascal. The Turing core is huge, 754 mm2, which is second only in size to GV100, which is 21.1 billion transistors with a die size of 815 mm2.

Unsurprisingly; Jensen did confirm GDDR6 would be present on the cards. It’s running at 14gbps and uses Samsung’s 16gb RAM. The Quadro RTX 8000 contains 48 GB RAM on a 384 bit memory bus, equalling to 672 GB/s bandwidth, while the RTX 6000 has ‘just’ a 256 bit bus, and 448 GB/s bandwidth and just 24 GB RAM.
It’s worth discussing NVLink too, offering up to 100GB/s bandwidth between two connected GPUs – which is pretty darn insane. This also allows the GPU to virtually share frame buffers. Of course, 100 GB/s isn’t as fast as the what the Quadro RTX 6000 can shunt data around locally (100GB/s vs 448 GB/s) but it should be pretty damn impressive. Thanks to NVLINK, Nvidia are touting the Quadro RTX 8000 as being capable of supporting up to 96GB RAM (48GB on each of the two cards).
| GPU | Memory | Memory with NVLink | Ray Tracing | CUDA Cores | Tensor Cores |
| Quadro RTX 8000 | 48GB | 96GB | 10 GigaRays/sec | 4,608 | 576 |
| Quadro RTX 6000 | 24GB | 48GB | 10 GigaRays/sec | 4,608 | 576 |
| Quadro RTX 5000 | 16GB | 32GB | 6 GigaRays/sec | 3,072 | 384 |
Here’s Nvidia’s official blurb concerning the RTX Quadros.
- New RT Cores to enable real-time ray tracing of objects and environments with physically accurate shadows, reflections, refractions and global illumination.
- Turing Tensor Cores to accelerate deep neural network training and inference, which are critical to powering AI-enhanced rendering, products and services.
- New Turing Streaming Multiprocessor architecture, featuring up to 4,608 CUDA® cores, delivers up to 16 trillion floating point operations in parallel with 16 trillion integer operations per second to accelerate complex simulation of real-world physics.
- Advanced programmable shading technologies to improve the performance of complex visual effects and graphics-intensive experiences.
- First implementation of ultra-fast Samsung 16Gb GDDR6 memory to support more complex designs, massive architectural datasets, 8K movie content and more.
- NVIDIA NVLink® to combine two GPUs with a high-speed link to scale memory capacity up to 96GB and drive higher performance with up to 100GB/s of data transfer.
- Hardware support for USB Type-C™ and VirtualLink™(1), a new open industry standard being developed to meet the power, display and bandwidth demands of next-generation VR headsets through a single USB-C™ connector.
- New and enhanced technologies to improve performance of VR applications, including Variable Rate Shading, Multi-View Rendering and VRWorks Audio.
So what about the GeForce GTX 2080 then?
Well, obviously here’s where things get a little sticky, as there’s no official information regarding these GPUs, but there’s certainly no shortage of information and speculation that points out the GPU. Most likely, we’ll be looking at the GTX 2080 as a cutdown RTX 5000 chip, which has a total of 3,072 CUDA cores. These numbers would certainly fit in with previous generations of how Nvidia have balanced the GTX 1080 and the P5000 GPU, with the P5000 having the same number of CUDA cores as the GTX 1080 (2,560). We did see the P6000 with 16GB GDDR5X RAM though, double that of the GTX 1080, and given the RTX 5000 has 16GB RAM, it’s likely we’ll see the same cuts here.

We don’t have clocks yet for the RTX 5000, but the RTX 8000 is running at 1.75GHz, so we can assume at least similar speeds will be seen here. Although we’re still on the 12nm process, there were rumors that Nvidia will push for better clock management and boosting for the RTX 20 series… although of course, custom cooled AIB cards will probably add a bit of extra speed anyway, just like with previous Nvidia cards.
In terms of the Nvidia RT cores and Tensor, the Tensor core number for the RTX 5000 has been cut from 576 to 384 (a fifty percent reduction). But whether this’ll be cut even further in the RTX 2080 (and 2070) isn’t confirmed. It’d not be surprising, given that it’d likely bring the cost down a little. As for RT cores, we see 10 GigaRays a second for the Quadro RTX 8000 reduced to 6 GigaRays… which should still be more than enough.

It’s also important to remember that while its very exciting Nvidia are pushing real time ray tracing, it’ll be awhile before its even slightly ‘normal’ in games. We know Metro Exodus is using it, and there are other games being worked on too – with Unreal Engine by Epic firmly embracing it. But; and that’s a big but, this isn’t something that’ll directly benefit you right now. We certainly aren’t gonna give you upgrade advice yet (even despite a few game benchmarks that we’ll get too in a moment) as there’s not enough reports on the consumer card. But if you happen to be the proud owner of a GTX 1080 Ti (or something similar) you might be better off waiting; either for custom cards to come out, prices to settle or to pick up the inevitable RTX 2080 Ti which’ll probably be on store shelves in the Q1 period (given Nvidia’s launch schedule of the GTX 1080 Ti and so on).
The fact is though, that Turing is very exciting. I am most curious as to how AMD will eventually answer back (be that with Vega 7nm for gamers, or more realistically, Navi) and if we’ll see Ray Tracing of some description on the GPU.

Although outside the scope of this article, with Microsoft so far invested in DirectX 12 and DXR, we can almost certainly make the assumption the next generation Xbox (known only as Project Scarlet right now) will likely have some type of Ray Tracing support. Sony are a question mark here. Navi is said to have been designed for Sony’s PlayStation 5, so whether Microsoft get a look in with Navi, or AMD are producing their own GPU for Microsoft, OR Microsoft use Nvidia or something entirely different is a bit of a question mark. But if Microsoft are gonna go with AMD (or we hear hardware ray tracing is supported in the PS5) it’ll give us insight into what AMD are planning with their next generation of GPUs for the desktop.
So what about Benchmarks then, eh? Well, of course – these could be fake – but it’s not very likely. We also cannot tell the GPU they’re being run on, as it’s only being reported as “Nvidia Graphics Device”. The important thing here though is the performance, which is quite frankly insanity. We’re looking at almost 70 to 80 FPS (depending upon the settings and date of the benchmark). To put that into some level of context, this is faster (or about on par) with what an Nvidia Titan V would be outputting – and if this is what we’ll be getting for the RTX 2080, I dread to think the performance of what the RTX 2080 Ti would be capable of.
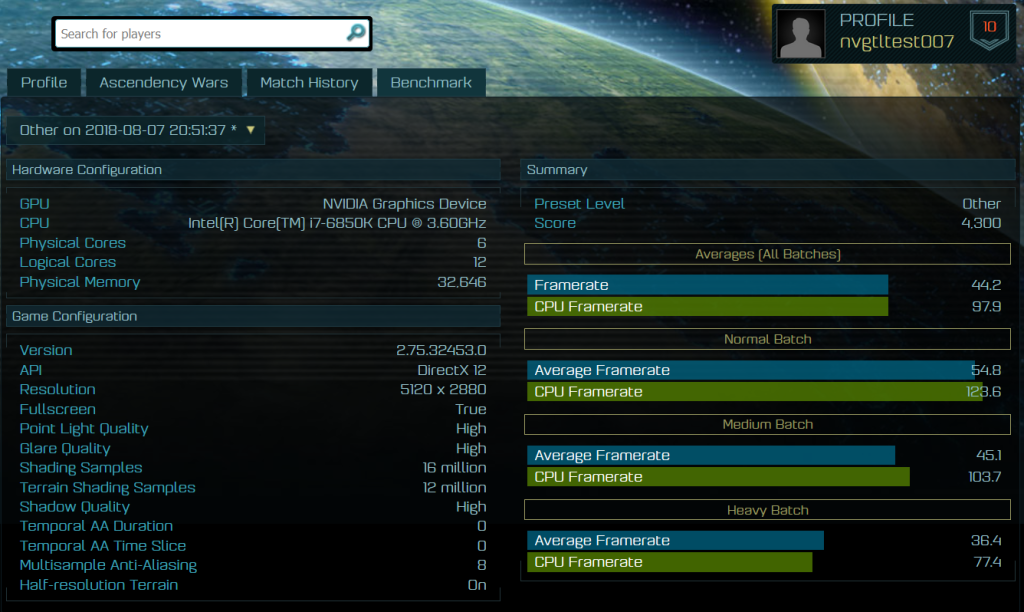
Given what we know of the TFLOPS performance of the Titan V (about 15 TFLOPS), it’s slower than the RTX 8000’s 16 TFLOPS so this does make sense; albeit we’re not taking into account other changes of the Turing architecture. So it’s probable here that performance varies because we’re seeing the hardware on different Turing GPUs and still quite early driver revisions. The GeForce GTX 1080 Ti isn’t capable of locking super demanding games to 4K 60FPS, so it’s possible the RTX 2080 could just about have the horsepower to do so… or at least come darn close.
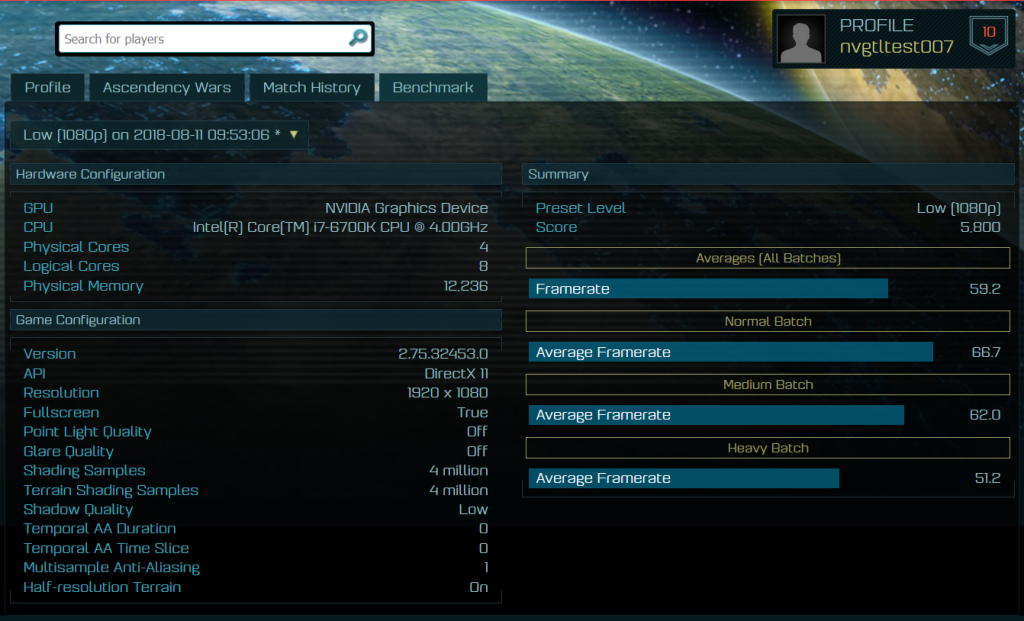
We can also see that the Quadro RTX 8000 seemed to use the default Nvidia blower (or at least a very similar design), thus it’s likely we’ll see similar for the GeForce RTX 2080, and not the rumored dual fan design (at least in theory). This likely means that we’re seeing 250W or less power consumption.
The Quadro RTX’s support Display Port 1.4, allowing up to 8K displays, and support for the VirtualLink standard. While there’s no VirtualLink headsets currently on the market, the major players all support this, so it’s only a matter of time before units go on sale. A single cable is capable of carrying power, video, data and it makes sense for the new GeForce RTX cards to support this too.

As for the next generation GeForces and support for NVLINK… well, it’s possible, and we’ll know the answer in about a week. But the presence of NVLINK on the Quadro cards doesn’t necessarily mean a yay or nay to what would be essentially an improved SLI for consumer boards. We have seen that leaked PCB, which did show fingers looking very similar to NVLINK, but it’s also possible that this board wasn’t the GeForce RTX 2080, and instead was a Quadro RTX. Nvidia haven’t been pushing SLI as much recently, but things can change at the drop of a hat – and if the company want a ray tracing future, particularly for gamers who demand high refresh rates and high resolutions, its doubtful a single card would pump out the performance, and possibly not even the theoretical RTX 2080 Ti.



